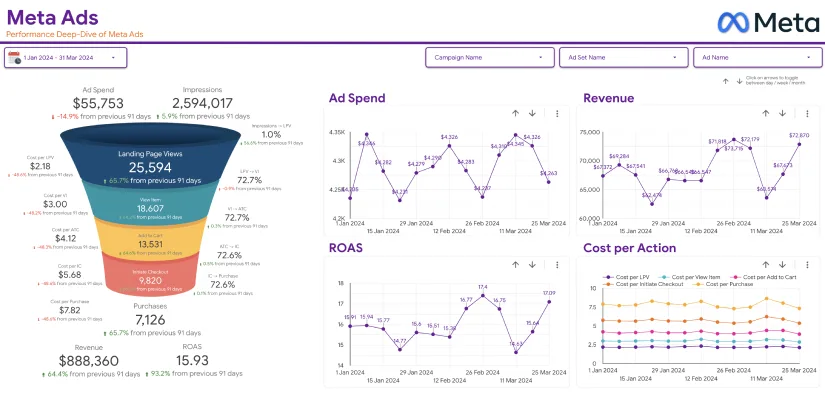
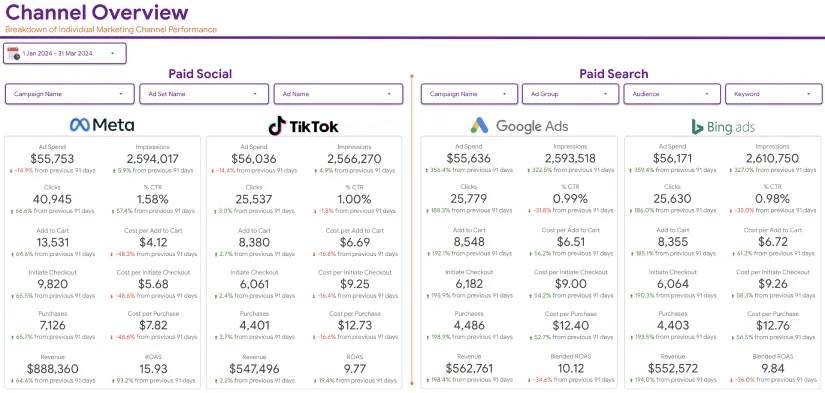
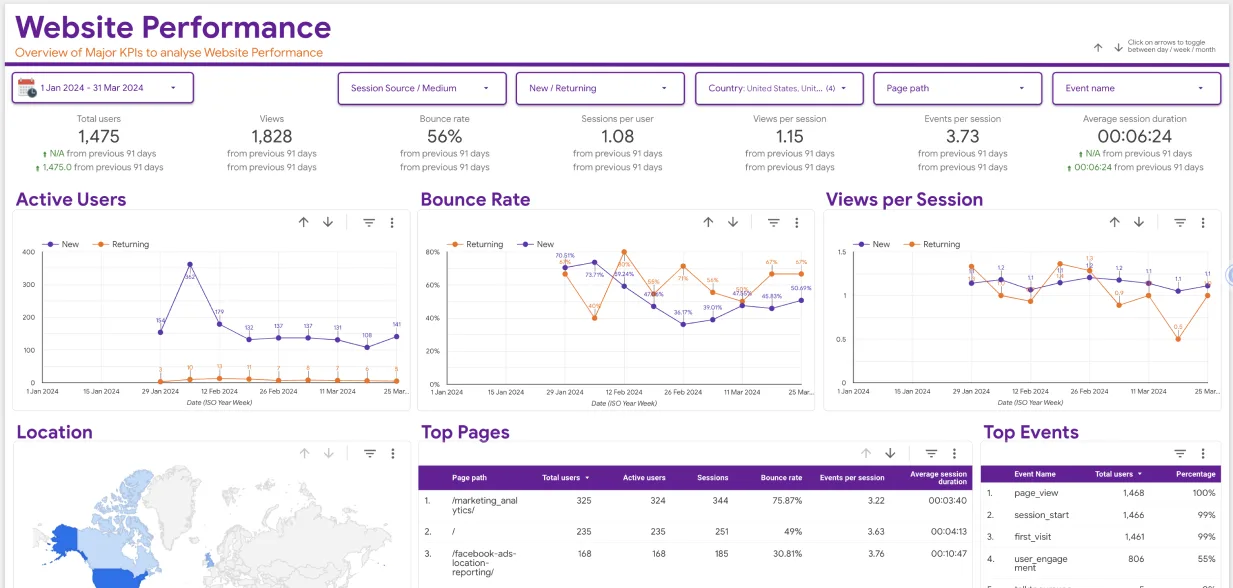
In the fast-paced digital landscape, businesses rely heavily on data-driven insights to make informed decisions. However, without a well-structured data pipeline, harnessing the power of data for analytics can be challenging. Building effective data pipelines is essential for seamless analytics integration, enabling organizations to extract valuable insights efficiently. In this article, we’ll explore five proven strategies to master the art of data flow and optimize your analytics workflow effortlessly.
Introduction
In today’s data-driven world, businesses are constantly seeking ways to leverage data effectively for gaining a competitive edge. Building effective data pipelines is the cornerstone of successful analytics integration, ensuring that data flows smoothly from source to destination, ready for analysis. Whether you’re a seasoned data engineer or a novice analyst, mastering the fundamentals of data pipeline architecture is crucial for unlocking the full potential of your data.
Understanding Data Pipelines
Data pipelines serve as the backbone of any analytics infrastructure, facilitating the seamless flow of data from various sources to downstream analytics systems. A well-designed data pipeline consists of interconnected stages that handle data ingestion, processing, transformation, and delivery. By orchestrating these stages effectively, organizations can ensure data integrity, reliability, and scalability throughout the analytics lifecycle.
Components of a Data Pipeline
- Data Ingestion: The process of collecting raw data from disparate sources such as databases, APIs, and streaming platforms.
- Data Processing: Transforming raw data into a structured format suitable for analysis, often involving cleaning, filtering, and aggregating operations.
- Data Storage: Storing processed data in a centralized repository or data warehouse for easy access and retrieval.
- Data Transformation: Applying business logic and algorithms to derive actionable insights from raw data.
- Data Delivery: Presenting analyzed data to end-users through visualization tools, dashboards, or reporting mechanisms.
Best Practices for Building Effective Data Pipelines
1. Embrace Modular Design
Break down your data pipeline into modular components, each responsible for a specific task or function. Modular design promotes reusability, scalability, and maintainability, allowing you to adapt your pipeline to evolving business needs with minimal effort.
2. Ensure Data Quality and Consistency
Prioritize data quality assurance at every stage of the pipeline to prevent errors, anomalies, and inconsistencies from propagating downstream. Implement robust data validation, error handling, and monitoring mechanisms to maintain data integrity and reliability.
3. Automate Wherever Possible
Leverage automation tools and frameworks to streamline repetitive tasks and workflows within your data pipeline. Automation reduces manual intervention, accelerates time-to-insight, and minimizes the risk of human errors.
4. Optimize for Performance and Scalability
Design your data pipeline with performance and scalability in mind, ensuring that it can handle increasing volumes of data without compromising throughput or latency. Employ parallel processing, caching, and distributed computing techniques to maximize efficiency and resource utilization.
5. Foster Collaboration and Documentation
Promote collaboration among cross-functional teams involved in building and maintaining the data pipeline. Document design decisions, configurations, and dependencies comprehensively to facilitate knowledge sharing and troubleshooting.
Building Effective Data Pipelines for Seamless Analytics Integration
Building effective data pipelines requires a combination of technical expertise, strategic planning, and continuous optimization. By following these proven strategies, you can streamline your analytics process, empower decision-makers with actionable insights, and drive business success in the data-driven era.
1. How do data pipelines facilitate analytics integration?
Data pipelines streamline the flow of data from diverse sources to analytics systems, ensuring seamless integration and analysis.
2. What are the key challenges in building data pipelines?
Key challenges include data quality assurance, scalability, performance optimization, and maintaining pipeline reliability.
3. Which tools are commonly used for building data pipelines?
Popular tools for building data pipelines include Apache Airflow, Apache Kafka, AWS Glue, and Google Dataflow.
4. How can organizations ensure data security in data pipelines?
Organizations can implement encryption, access controls, and monitoring measures to safeguard sensitive data within data pipelines.
5. What role does data governance play in data pipeline management?
Data governance frameworks establish policies, processes, and controls for ensuring data quality, compliance, and security throughout the pipeline lifecycle.
6. How can organizations measure the effectiveness of their data pipelines?
Organizations can track key performance indicators (KPIs) such as data latency, throughput, error rates, and pipeline uptime to assess the effectiveness of their data pipelines.
Conclusion
Mastering the art of building effective data pipelines is essential for organizations seeking to harness the full potential of their data for analytics. By implementing the strategies outlined in this article and embracing a culture of continuous improvement, you can create robust, scalable, and resilient data pipelines that drive actionable insights and fuel business growth.
Looking to optimize your analytics workflow? Get in touch with Eaglytics-Co and Learn more about building effective data pipelines for seamless analytics integration!